Tutorial - Advanced - CouchDB

This is the third part of a series of articles to show how to build a full solution with the Convector Suite. This part assumes you either finished the previous part or downloaded the backend for this project like this:
Once you are ready this tutorial will walk you through the following topics:
- You will learn how to make advanced queries to the WorldState:
Advanced Queries
The storage in Hyperledger Fabric works as follows:

The actual ledger is always stored in the peers. Peers have one or multiple secure runtimes in the form of containers and there is where your code runs. The ledger keeps all the data of transactions, even "read requests", in the form of blocks that are generated by the Ordering Service.
A read-only database known as the WorldState is generated every time the ledger changes - this database includes just the final computed version of the ledger - so for example whilst the ledger keeps all the permutations and changes in one model, the WorldState just keeps the latest resulting version of the model. This makes queries much more efficient than querying the ledger directly, enabling for complex queries and pre-built views.
Even if the CouchDB (which could also be LevelDB) is accessible through http and you could "modify" its contents, it will be regenerated every time.
As you can see from the diagram above the Client Application could technically communicate directly to the CouchDB, andeven if that's possible the preferred way is to query the WorldState through the Peer.
Complex queries through the peers - mango queries
Let's make a simple getAll function and then let's create a getByAttribute function to be able to query people based on some attributes.
You can notice the two new functions. One is a getAll that at the end queries the CouchDB for all the registries and the other one is a filter by attribute function called getByAttribute.
Beware that a getAll function may not be the best idea for your case since as the data grows in registries it may be too heavy for the peer to be returning all the items of a Model and process requests at the same time.
The getAll function is fairly straight forward, you pass the data type you want to query, and it will find the objects with that type for you and return them. We do a toJSON there to make sure we return the object with the actual property names.
On the other hand, the getByAttribute uses a much more complex syntax, what we are doing right here is to perform a Mango Query in which we are telling the engine to find inside of the attributes array a model where a certain attribute with certain name has certain value. We could for example query all the people with the same birth-year. Really useful right?
Let's try this in a unit test first (best practices, remember?).
Change the contents of the file ./packages/person-cc/tests/person.spec.ts with this:
Check out the latest functions:
- should get all the people
- should get all the people with the birth-year 1993
- should get zero people with the birth-year 1990
Run it and see the results npm test
Like this, we are making much more complex queries straight from the chaincode. Deploy the code and try it from the Blockchain too.
You can find more information about Mango Queries and try other combinations yourself!
Working with Views
Until today (April 2019) there's no official way to work with CouchDB Views on Hyperledger Fabric as it is with Indexes (see next section). But the good news is that the CouchDB connected to a peer gets its data regenerated but not the configurations, so there are a few workarounds, such as creating the views json folder and installing them with a script to automate it.
See more on CouchDB Views here. From this link, Views as useful for:
- Filtering the documents in your database to find those relevant to a particular process.
- Extracting data from your documents and presenting it in a specific order.
- Building efficient indexes to find documents by any value or structure that resides in them.
- Use these indexes to represent relationships among documents.
- Finally, with views you can make all sorts of calculations on the data in your documents. For example, if documents represent your company’s financial transactions, a view can answer the question of what the spending was in the last week, month, or year.
In the end, Views are functions that can use patterns such as map and reduce to emit data in a pre-compiled way that is helpful for your business.
Let's create a View to filter by the type property. This way, we can just query the view directly without needing to filter by the type property.
A JSON like this would do the work:
How can you upload this? A simple way is to create a script that communicates directly to your CouchDB container.
You will also need the JSON we saw before but formatted in the right JSON structure.
Place both files in a folder in the root ./views and run it from the root like this ./views/install.sh
See the results by going to the CouchDB of the first peer and compare the results from All Documents to the ones in person/Views/all.
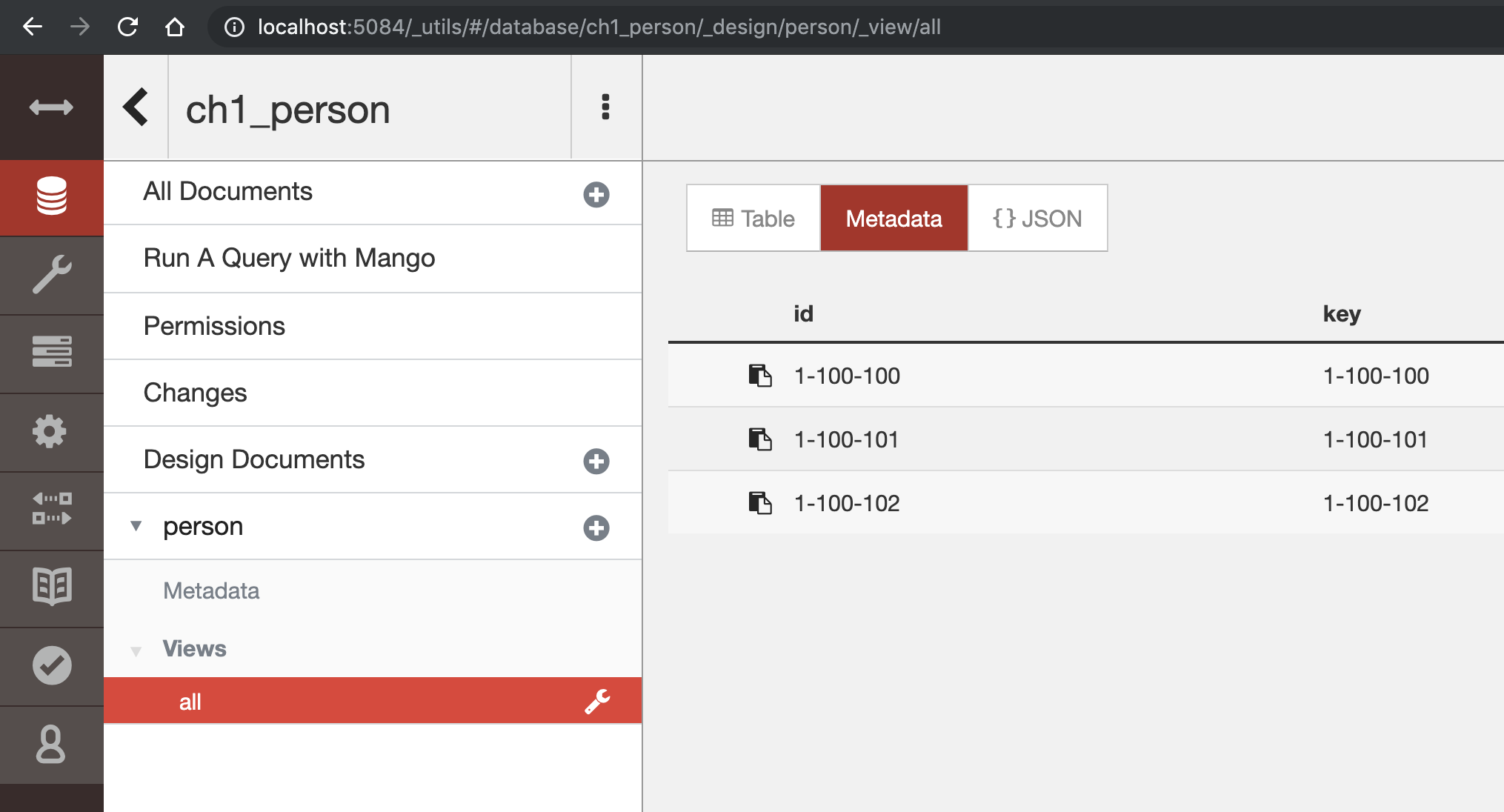
Note that since this is not done from a chaincode configuration (like indexes later), Views are not replicated automatically so you would need to install them on each CouchDB server.
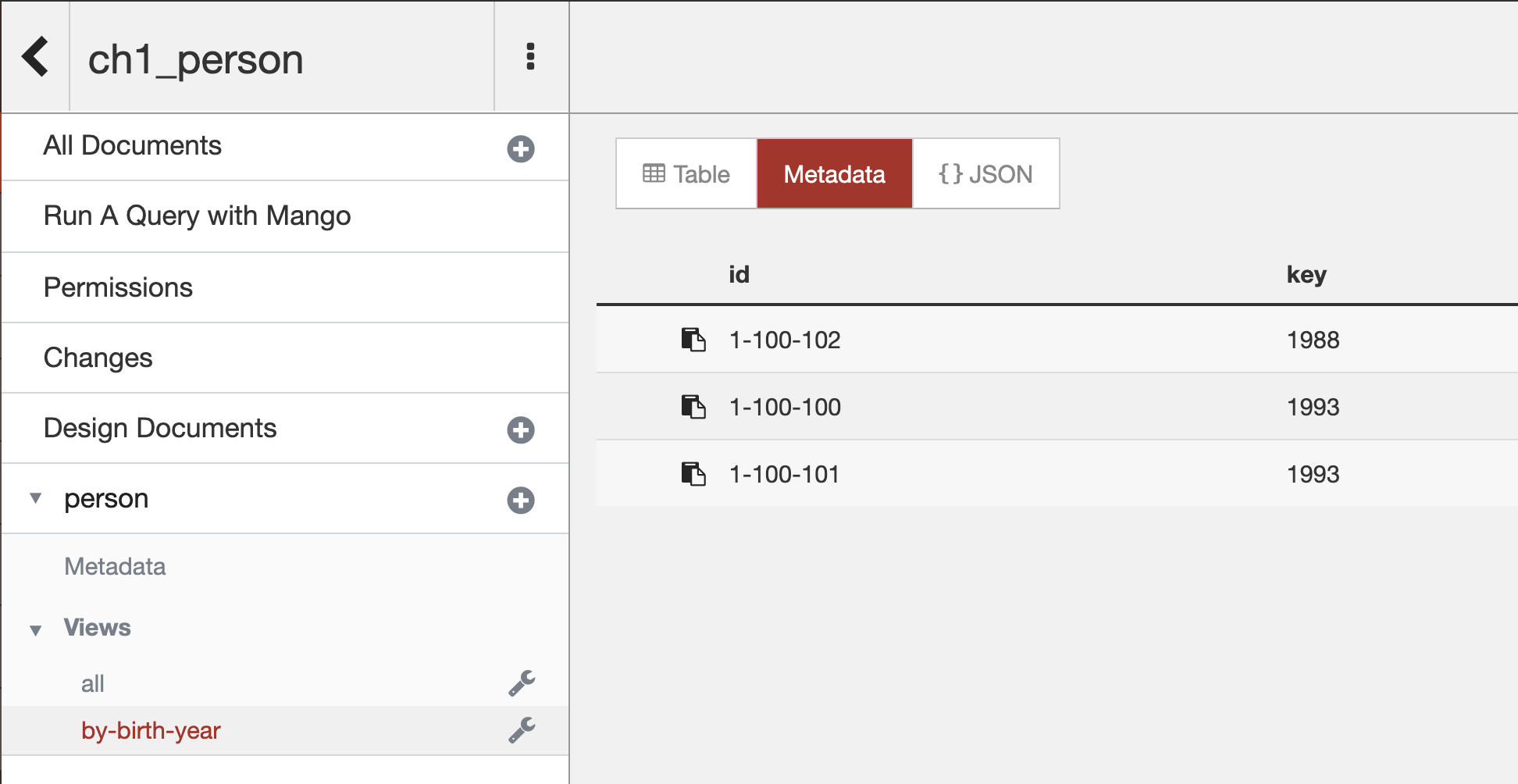
Another example is emitting documents by a different Id so that we could group data by a nested property, such as the birth-year inside of the attributes array:
This function is filtering if a birth-year property exists in the attributes array of each object and then, emitting the object with the value of the birth-year as the key. The results of this view could then be grouped by the birth-year in a front end or report.
Update the ./views/person.json file with this:
You will need to remove the existing View we previously installed:
And then re-run the installation script ./views/install.sh
Go and see the results by yourself here.
Call the CouchDB directly
Calling the CouchDB directly requires
Let's create a CouchDB query to get all the items in the view we just created called all.
As you can see in this new code for the ./packages/server/src/controllers/person.controller.ts a few things are going on:
- A BaseStorage is initialized.
- A call to the view que created before is also made.
- And it's exposed as an API endpoint.
Re run the server and try it with a Curl request curl http://localhost:8000/person.
Indexes
As stated in the official Fabric Docs for CouchDB "Indexes allow a database to be queried without having to examine every row with every query, making them run faster and more efficiently. Normally, indexes are built for frequently occurring query criteria allowing the data to be queried more efficiently. To leverage the major benefit of CouchDB – the ability to perform rich queries against JSON data – indexes are not required, but they are strongly recommended for performance. Also, if sorting is required in a query, CouchDB requires an index of the sorted fields."
To learn more about indexes please refer to the official Fabric documentation.
This part of the tutorial will focus on how to get them to work with Convector.
As you may already know, Convector runs natively, that means that the code you create is transpiled from Typescript, enhanced with some patterns from Convector, and then placed in the container that runs it. This means that you can stick to any pattern that exists in Fabric. Indexes as you can see in the Hyperledger Fabric documentation require a JSON file that needs to be included as part of the package.
With Convector, when the code is packaged (usually there's a task called cc:package in the root of your project) it gets transpiled, enhanced, and copied to a folder called chaincode-* where * is the name you gave to it. So, to get indexes to work with Convector you just need to copy the config JSON file required inside of that folder.
The paths are required to follow that standard as a requirement from Fabric - see other examples without Convector here. For example in this laboratory the folder would look like this:
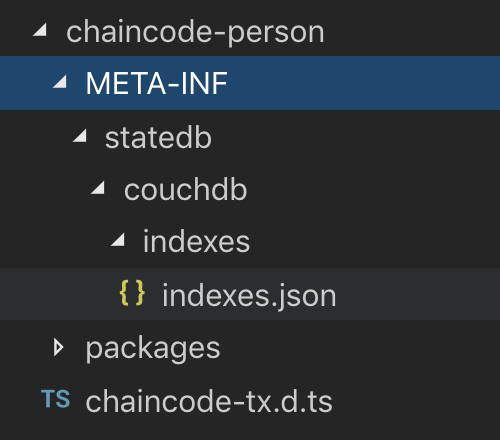 With the json in the right place you can see it configured in the CouchDB server as you upload your code.
With the json in the right place you can see it configured in the CouchDB server as you upload your code.
 Note that due to the way that the CLI created the setup for you, if you just copy the index JSON file it will be erased every time your code compiles, so for you to test this out in your setup, please follow the instructions in the next section.
Note that due to the way that the CLI created the setup for you, if you just copy the index JSON file it will be erased every time your code compiles, so for you to test this out in your setup, please follow the instructions in the next section.
Automating the compilation process
As soon as you run the cc:package task your chaincode-person folder will be completely wiped out and recreated with the latest version - so, if your chaincode-person folder needs your JSON indices file, where to place it and how to copy it?
Here to save the indexes config file
We recommend that you create a root folder called ./indexes and place all of your indexes config files there.
Let's create a really simple index files in ./indexes/indexes.json for the type field.
Once you pasted these contents, all you need to do is automating somehow that after the code is ready and compiled, it can be pasted in the right place so that Hurley can take that code and upload it to your peers.
We would need to apply some changes to our package.json file.
Pay special attention to the cc:package and copy:indexes tasks, as they have changes.
In the case of copy:indexes which a new task, it creates the folder inside of the compiled package and then copies all the contents for ./indexes in the root of your project to that path that was just created.
Then, inside of cc:package we make sure that after the code is recompiled, the copy task will be executed.
Run this project again to see the results, either re run everything, or upgrade your existing chaincode npm run cc:upgrade -- person 3